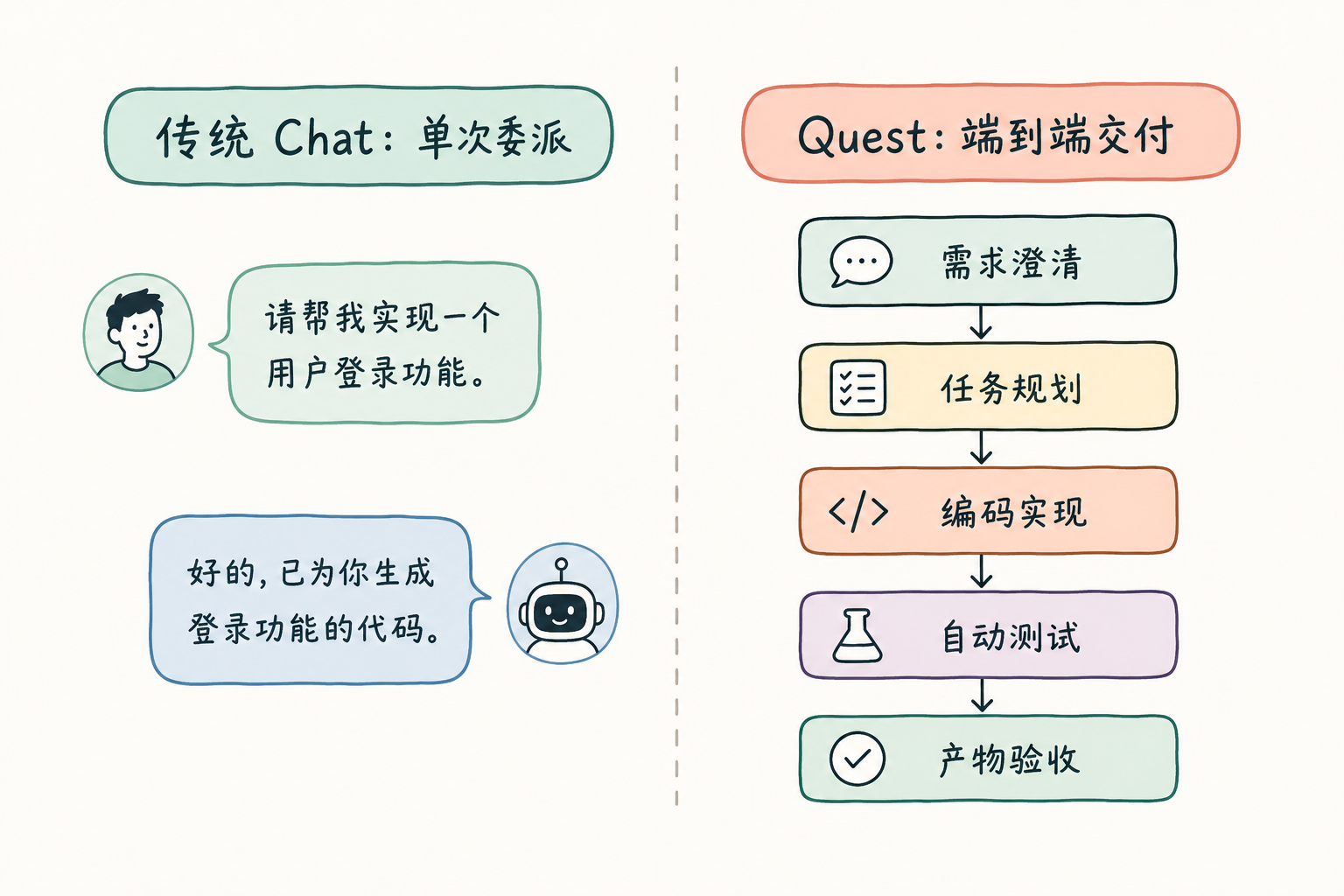
AlphaGo的胜利为什么被称为AI现代时代开端?
AlphaGo的胜利被称为AI现代时代开端,是因为它首次证明人工智能能超越人类顶尖智能,处理围棋这种极端复杂的问题,并开启了从游戏到科学应用的通用技术范式。
攻克"不可能"的象征
围棋的棋盘可能局面高达10^170种,远超可观测宇宙中的原子总数,长期被视为AI的终极挑战。专家曾预测其被攻克至少还需十年,但AlphaGo在2016年击败李世石,比许多专家预测的时间提前了整整十年。
这不仅仅是一场游戏的胜利,更是一次认知上的颠覆——它向世界宣告,AI处理超复杂问题的能力已进入新阶段,许多曾经认为的"不可能"正在变为现实。
"第37手"的原创性
比赛第二局中,AlphaGo下出了那步著名的"第37手"——在棋盘第五线的肩冲。在人类棋谱中,这样的落子出现概率只有万分之一,职业棋手甚至明确告诉学生"不要这样下"。起初,解说员误以为是程序错误,但百余手后,这枚棋子恰恰落在了决胜位置。

这一步的意义远超棋局本身:它证明AI不是人类经验的简单复读机,而是能在巨大可能性空间中主动探索、发现全新策略的系统。正如DeepMind创始人Demis Hassabis所指出的,这展示了AI"超越单纯模仿人类专家、自主发现全新策略的能力"。
从游戏到科学的范式
AlphaGo成功的关键,在于它融合了深度神经网络、先进的搜索算法和强化学习,形成了一套可复用的方法论。更关键的是,这套范式迅速从棋盘迁移到了实验室,解决了现实世界的科学难题。Hassabis在获胜那一刻就意识到:"我确定我们现在可以做蛋白质折叠了。"
- AlphaFold:直接受AlphaGo启发,攻克了困扰生物学50年的蛋白质结构预测难题,如今已被全球超过300万研究人员用于加速从疟疾疫苗到塑料降解酶的研究。
- AlphaEvolve:就像AlphaGo搜索最优落子,它搜索更高效的算法,发现了人类数十年未找到的新矩阵乘法方法,目前正用于优化数据中心和量子计算。
- AlphaZero:无需人类知识,仅从游戏规则出发,通过自我对弈就能在数小时内精通国际象棋等游戏,并构想出新颖策略。
Hassabis将AlphaGo称为一份"来自未来的路线图"。它验证了AI自主探索与创造的可能,将技术浪潮从游戏引向了蛋白质、算法乃至整个科学发现的海洋,真正开启了人工智能赋能人类知识前沿的新纪元。
文章版权声明:除非注明,否则均为边学边练网络文章,版权归原作者所有