一、面试被问“百万请求架构”,答完却被反问“还有吗?”
职场面试中,Java/SpringBoot工程师最怕遇到的,就是这类开放性技术题:“如何设计一个每天处理数百万请求,还能执行复杂后端任务的系统?”
有位软件工程师朋友,最近就遭遇了这个灵魂拷问。他胸有成竹地说出了数据库优化、Redis缓存、Kafka消息队列、微服务限流这一套标准答案,本以为能顺利通关,没想到面试官却轻轻皱了皱眉,追问了一句:“就这些?还有遗漏的吗?”
这句话瞬间让他慌了神——自己深耕后端多年,能想到的性能优化手段全说了,到底漏了什么?
其实不止他,很多资深工程师都有一个共识:代码层面的优化终究有限,真正支撑百万请求稳定运行的,除了技术选型,还有很多被忽略的细节和运维逻辑。今天就结合真实职场案例,拆解百万请求系统的完整架构,帮所有Java工程师避坑,下次面试再遇到这类问题,直接从容应对。
关键技术补充说明
文中核心用到的4项关键技术,均为开源免费,是后端架构的“标配”,其GitHub星标数量如下,足以证明行业认可度:
1. SpringBoot:Java后端开发框架,GitHub星标70.8k+,开源免费,简化配置,是企业级开发的首选框架,也是面试高频考点。
2. Redis:高性能缓存数据库,GitHub星标61.5k+,开源免费,支持多种数据结构,能有效减少数据库访问压力,提升响应速度。
3. Kafka:分布式消息队列,GitHub星标26.3k+,开源免费,支持高吞吐量、高可靠性,是实现事件驱动、并行处理的核心工具。
4. 布隆过滤器(BloomFilter):概率型数据结构,开源免费,无单独GitHub仓库(常集成于Redis、Guava等工具),能快速判断元素是否存在,大幅提升系统性能。
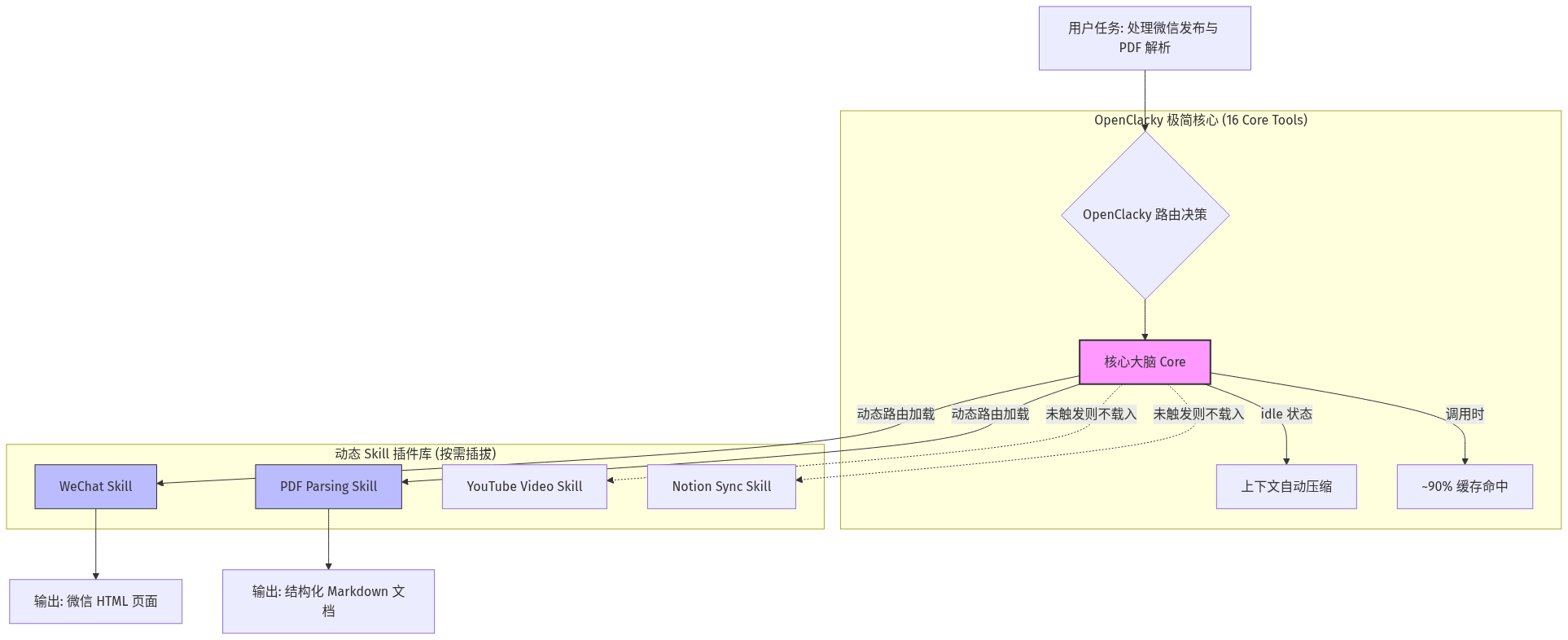
二、核心拆解:百万请求系统的5大核心操作,一步都不能少
要支撑每天/每小时数百万次请求,同时保证后端复杂任务正常执行,绝非单一技术就能实现,需从“数据库、缓存、消息队列、服务稳定性、用户体验”5个维度层层递进,每一步都有明确的操作方法,照搬就能用。
1. 数据库优化:筑牢性能基石,避免“拖后腿”
数据库是系统的“数据仓库”,一旦读写性能拉胯,哪怕前端、缓存做得再好,整体系统也会卡顿。核心操作只有2个,简单易落地:
一是优化数据库读写性能,针对高频查询场景建立合适的索引,减少全表扫描;二是调整数据库连接池,根据请求量合理设置连接数,避免连接过多导致资源耗尽,或连接过少导致请求排队。
比如MySQL数据库,可通过调整max_connections(最大连接数)、wait_timeout(连接超时时间)等参数,适配百万请求的并发场景,避免出现“连接耗尽”的报错。
2. Redis缓存:减少数据库访问,提速不止一个档次
频繁访问数据库是系统性能瓶颈的主要原因之一,而Redis作为高性能缓存,能将常用数据缓存到内存中,让请求无需访问数据库就能直接返回结果,速度提升10倍以上。
核心逻辑:将高频访问的数据(比如用户信息、商品基础数据)缓存到Redis中,设置合理的过期时间,避免缓存雪崩、缓存击穿;同时接受“占用更多内存”的代价,换取更快的响应速度——对于百万请求系统来说,内存成本远低于性能损耗的成本。
示例代码(SpringBoot集成Redis缓存,简洁易运行):
// 1. 引入依赖(pom.xml) org.springframework.boot spring-boot-starter-data-redis // 2. 配置Redis(application.yml)spring: redis: host: 127.0.0.1 port: 6379 password: 123456 lettuce: pool: max-active: 100 # 最大连接数,适配高并发 max-idle: 20 # 最大空闲连接 min-idle: 5 # 最小空闲连接// 3. 缓存使用示例@Servicepublic class UserService { @Autowired private RedisTemplate redisTemplate; @Autowired private UserMapper userMapper; // 缓存用户信息,key为用户ID,过期时间1小时 public User getUserById(Long userId) { String key = "user:" + userId; // 先查缓存 User user = (User) redisTemplate.opsForValue().get(key); if (user == null) { // 缓存未命中,查数据库 user = userMapper.selectById(userId); // 存入缓存,设置过期时间3600秒 redisTemplate.opsForValue().set(key, user, 3600, TimeUnit.SECONDS); } return user; }} 3. Kafka消息队列:实现并行处理,打破串行瓶颈
如果后端任务是串行执行(先执行A,再执行B,最后执行C),哪怕单步任务耗时很短,在百万请求的并发场景下,也会出现严重的排队拥堵。而Kafka消息队列,能通过事件驱动开发,让多个任务并行执行,大幅提升处理效率。
核心逻辑:将用户请求放入Kafka的队列/主题中,不同的后端服务分别监听对应的主题,同时接收事件并处理——比如请求A触发任务B、C、D,无需等待B执行完再执行C,而是B、C、D同时执行,极大缩短了单个请求的处理时间。
示例代码(SpringBoot集成Kafka,实现消息发送与接收):
// 1. 引入依赖(pom.xml) org.springframework.boot spring-boot-starter-kafka // 2. 配置Kafka(application.yml)spring: kafka: bootstrap-servers: 127.0.0.1:9092 producer: key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: request-group key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer// 3. 消息发送者(处理用户请求,发送到Kafka)@Servicepublic class RequestProducer { @Autowired private KafkaTemplate kafkaTemplate; // 发送请求到Kafka主题 public void sendRequest(String requestId, String requestContent) { // 主题名:request-topic,key:请求ID,value:请求内容 kafkaTemplate.send("request-topic", requestId, requestContent); }}// 4. 消息消费者(并行处理任务B)@Servicepublic class TaskBConsumer { @KafkaListener(topics = "request-topic") public void processTaskB(ConsumerRecord record) { String requestId = record.key(); String requestContent = record.value(); // 执行任务B的业务逻辑 System.out.println("任务B处理请求:" + requestId); }}// 5. 消息消费者(并行处理任务C)@Servicepublic class TaskCConsumer { @KafkaListener(topics = "request-topic") public void processTaskC(ConsumerRecord record) { String requestId = record.key(); String requestContent = record.value(); // 执行任务C的业务逻辑 System.out.println("任务C处理请求:" + requestId); }} 4. 服务稳定性:限流、熔断,避免系统雪崩
百万请求的并发场景下,一旦某个服务出现故障,很容易引发连锁反应,导致整个系统崩溃。因此,必须做好3点防护,保障服务弹性:
一是微服务拆分:将复杂系统拆分为多个独立的微服务(比如用户服务、订单服务、支付服务),单个服务故障不会影响整体系统运行;二是API限流:限制每个接口的请求频率,避免某一个接口被高频请求击垮,常用工具如Sentinel;三是熔断机制:当某个服务(尤其是第三方API服务)出现异常时,及时熔断,避免持续调用导致资源耗尽,同时提供降级方案。
此外,还要做好带关联ID的日志记录——每个请求分配一个唯一的关联ID,贯穿整个请求链路,一旦出现问题,能快速定位到异常环节,减少排查时间。
5. 概率过滤器:前置拦截,进一步提升性能
对于一些高频查询场景(比如用户名是否可用、手机号是否已注册),哪怕用了Redis缓存,频繁访问缓存也会产生一定的性能损耗。这时,概率过滤器(如布隆过滤器、布谷鸟过滤器)就能派上大用场。
核心逻辑:概率过滤器是一种特殊的数据结构,能100%判断某个元素“不存在”,但可能以极低的误报率判断元素“存在”。将高频查询的元素(比如已注册的用户名)存入过滤器,请求过来时,先通过过滤器判断——如果过滤器显示“不存在”,直接返回结果,无需访问缓存和数据库;如果显示“存在”,再走“缓存→数据库”的流程,大幅减少无效请求。
示例代码(Guava实现布隆过滤器,可直接运行):
// 1. 引入依赖(pom.xml) com.google.guava guava 32.1.3-jre // 2. 布隆过滤器使用示例(用户名判断)public class BloomFilterDemo { public static void main(String[] args) { // 1. 创建布隆过滤器:预计存储100万条数据,误报率0.01 int expectedInsertions = 1000000; double fpp = 0.01; BloomFilter bloomFilter = BloomFilter.create( Funnels.stringFunnel(Charset.defaultCharset()), expectedInsertions, fpp ); // 2. 存入100万条已注册用户名 for (int i = 0; i < 1000000; i++) { bloomFilter.put("user_" + i); } // 3. 判断用户名是否存在 String username1 = "user_123456"; // 已注册 String username2 = "user_1000001"; // 未注册 // 存在:可能存在(误报率0.01),不存在:绝对不存在 System.out.println("username1是否存在:" + bloomFilter.mightContain(username1)); // true System.out.println("username2是否存在:" + bloomFilter.mightContain(username2)); // false }} 6. 用户体验优化:异步处理,避免用户等待
如果后端处理某个请求需要较长时间(比如生成复杂报表、处理大量数据),让用户一直等待会严重影响体验。正确的做法是:用户发起请求后,系统立即返回响应,告知用户“请求正在处理中”,然后异步执行后端任务,任务完成后再通过短信、站内信等方式通知用户。
这样既避免了用户长时间等待,也不会让用户误以为请求失败,大幅提升用户满意度。

三、辩证分析:这些优化手段,真的完美无缺吗?
上面提到的5大核心操作,确实能支撑百万请求系统稳定运行,也是面试中的“标准答案”。但资深工程师都清楚,没有完美的架构,每一种优化手段都有其局限性,背后都隐藏着需要权衡的问题。
先说说Redis缓存:它确实能提升速度,但会占用更多内存,一旦缓存过期、缓存雪崩,反而会导致数据库压力骤增,甚至崩溃;而且缓存与数据库的数据一致性,也是需要重点解决的问题——如果数据库数据更新了,缓存没有及时更新,就会出现数据不一致的情况。
再看Kafka消息队列:并行处理确实能提升效率,但也增加了系统的复杂度。消息的顺序性、消息丢失、消息重复消费等问题,都需要额外开发逻辑来解决;而且Kafka本身的部署、运维,也需要投入更多的人力和资源。
最容易被忽略的,是概率过滤器的更新问题。文中提到,布隆过滤器适合判断用户名是否可用,但如果系统每天有上百上千个新用户注册,如何更新所有实例上的布隆过滤器?如果采用“推送更新”,会增加系统开销;如果采用“拉取更新”,又会存在一定的延迟——比如每6小时更新一次,那么最近6小时内注册的用户名,过滤器无法识别,可能会出现误判。
还有一个关键问题:很多工程师都专注于代码层面的优化,却忽略了运维的重要性。文中的工程师也坦言,自己只关注代码在开发环境、测试环境的运行速度,却从来没有考虑过生产环境的扩展——而百万请求系统的稳定运行,离不开运维人员对云环境(如AWS、阿里云)的优化,根据请求量动态添加资源,这才是系统扩展性的核心。
更现实的是:代码层面的优化空间有限,哪怕你把代码写得再高效,一旦请求量突破服务器的承载极限,所有优化都显得苍白无力。这时,运维的资源扩容、负载均衡,才是解决问题的关键。
所以,一个能处理百万请求的系统,从来不是“代码优化”就能搞定的,而是“代码优化+运维支撑+业务适配”的综合结果。我们既要做好前端的性能优化,也要重视后端的稳定性设计,更不能忽略运维的重要性——这三者缺一不可。
四、现实意义:搞懂这套架构,到底能帮你解决什么问题?
对于Java/SpringBoot工程师来说,搞懂百万请求系统的架构设计,不仅仅是为了应对面试,更能解决实际工作中的诸多痛点,甚至决定你的职业上限。
首先,解决面试痛点:这类“高并发系统设计”题,是中高级Java工程师面试的必考题,很多人因为回答不全面、不深入而错失offer。掌握文中的5大核心操作+辩证思考,下次面试再遇到这类问题,既能说出标准答案,又能指出优化手段的局限性,轻松脱颖而出。
其次,解决工作痛点:随着业务发展,很多系统会从“万级请求”升级到“百万请求”,如果前期架构设计不合理,后期会出现性能瓶颈、系统崩溃等问题,重构成本极高。提前掌握这套架构思路,能在系统设计初期就规避风险,减少后期维护成本。
最后,提升职业竞争力:在后端开发领域,“高并发、高可用”是核心竞争力。能独立设计、优化百万请求系统的工程师,薪资待遇远高于普通后端工程师,而且更容易获得晋升机会——毕竟,这类人才是企业的核心需求。
更重要的是,这套架构思路背后,是“权衡与取舍”的思维——在性能、成本、复杂度之间找到平衡点,这才是资深工程师与普通工程师的本质区别。
五、互动话题:你在设计高并发系统时,踩过哪些坑?
百万请求系统的架构设计,没有标准答案,只有最适合业务的方案。文中提到的优化手段,或许在你的实际工作中,还有更好的替代方案;也可能你在设计高并发系统时,踩过很多别人没遇到过的坑。
评论区聊聊:你在工作中,是如何设计高并发系统的?有没有遇到过Redis缓存雪崩、Kafka消息丢失的问题?又是如何解决的?
另外,对于布隆过滤器的更新问题,你更倾向于“推送更新”还是“拉取更新”?欢迎分享你的经验,一起交流学习,共同提升!